
计算机组成原理-学习笔记8-cache
计算机组成原理-学习笔记8-cache
主板内储存器:寄存器 / Cache / 主存
Cache
内存墙:CPU运算速度比内存的速度快,且两者差距不断扩大
解决: CPU和内存之间增加Cache
- 在使用主存(相对大而慢)之余,添加一块小而快的cache
- Cache位于CPU和主存之间,可以集成在CPU内部或作为主板上的一个模块
- Cache中存放了主存中的部分信息的副本
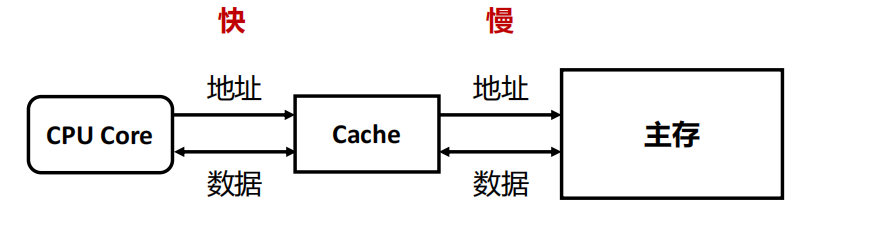 image-20221101165348656
image-20221101165348656
工作流程
• 检查(Check):当CPU试图访问主存中的某个字时,首先检查这个字是否在cache中
- 检查后分两种情况处理:
• 命中(Hit):如果在cache中,则把这个字传送给CPU
• 未命中(Miss):如果不在cache中, 则将主存中包含这个字固定大小的块(block)读入cache中,然后再从cache传送该字给CPU
1.Questions
如何判断是命中还是未命中?
• CPU通过位置对主存中的内容进行寻址,不关心存储在其中的内容
• Cache通过标记(tags)来标识其内容在主存中的对应位置(tag存放在块之前)
如果未命中,为什么不直接把所需要的字从内存传送到CPU?
以便再次访问时命中。
局部性原理:处理器频繁访问主存中相同或相邻位置的现象。
- 时间局部性 :短时间周期访问相同位置
- 空间局部性:短时间周期内访问相邻储存位置
- 顺序局部性:线性排列(如数组)
如果未命中,为什么从内存中读入一个块而不只读入一个字?
利用空间局部性。
- 块是预先划分好的
 image-20221101172526290
image-20221101172526290
使用Cache后需要更多的操作,为什么还可以节省时间
假设p是命中率, 𝑇𝐶 是cache的访问时间, 𝑇𝑀 是主存的访问时间,使用cache时的平均访问时间𝑇𝐴为:
𝑇𝐴 = 𝑝 × 𝑇𝐶 + 1 − 𝑝 × 𝑇𝐶 + 𝑇𝑀
= 𝑇𝐶 + (1 − 𝑝) × 𝑇𝑀
命中率p越大, 𝑇𝐶越小, 效果越好(降低TM很难,故要么提高p要么减少TC)
如果想要 𝑇𝐴 < 𝑇𝑀, 必须要求
- 𝑝 > 𝑇𝐶 / 𝑇𝑀
难点:cache的容量远远小于主存的容量(随机访问时𝑝 = Cache容量 /主存容量)
2.未命中的原因
义务失效(Compulsory Miss)/ 冷启动失效(Cold Start Miss)
- 第一次访问一个块时
• 例如:第一次访问一个数组,会发生义务失效
- 容量失效 (Capacity Miss)
• Cache无法保存程序访问所需的所有数据块,则当某数据块被替换后,又重新被访问,则发生失效
• 例如: cache大小为8KB,如果需要重复访问一个16KB大小的数组,数组无法全部放入cache,会发生容量失效
- 冲突失效(Conflict Miss)
• 多个存储器位置映射到同一Cache位置
• 例如:有两个4KB大小的数组都映射到了相同的地址,需要来回访问,则发生冲突失效
3.设计Cache所需考虑要素
3.1Chche容量
扩大cache容量带来的结果:
good: 增大了命中率𝑝
bad: 增加了cache的开销和访问时间 𝑇𝐶
3.2映射功能
1.直接映射:
地址中最高𝑛位, 𝑛 = 𝑙𝑜𝑔2𝑀 − 𝑙𝑜𝑔2C**(M为块的数量)**
每个块映射到一个固定可用的cache行中.
假设𝑖是cache行号,𝑗是主存储器的块号,𝐶是cache的行数,则i = j mod c
(同行号则低l𝑜𝑔2 𝐶位相同)
主存地址映射为:标记 | Cache行号 | 块内地址
 image-20221103162423116
image-20221103162423116
- 主存标记与字块标记比较
- 未命中,则说明映射到同mod块,需替换
优缺点
- 优点
- 简单
- 快速映射
- 快速检查
- 缺点
- 抖动现象(Thrashing):如果一个程序重复访问两个需要映射到同一行中,且来自不同块的字,则这两个块不断地被交换到cache中,cache的命中率将会降低,即发生冲突失效
- 适合大容量的cache
- 行数变多,发生冲突失效的概率降低
- 硬件电路简单,增大容量对𝑇𝐶的影响不明显,且能增大p
2.关联映射
一个主存块可以装入cache任意一行
地址中最高𝑛位, 𝑛 = 𝑙𝑜𝑔2𝑀(M为块的数量)
主存地址映射为:标记 | 字
示例
• 假设cache有4行,每行包含8个字;主存中包含128个字。访问主存的地址长度为7=log2(128)位,则:
• 最低的3位:块内地址
• 最高的4位:块号,记录为Cache标记
优缺点
• 优点
• 避免抖动
• 缺点
• 实现起来比较复杂
• Cache搜索代价很大,即在检查的时候需要去访问cache的每一行
• 适合容量较小的cache
• 小容量更容易发生冲突失效
• 小容量检查的时间短
3.组关联映射
结合上两种映射方式的优点(也结合了缺点):
- Cache分为若干组,每一组包含相同数量的行,每个主存块被映射到固定组的任意一行
- 假设𝑠是cache组号,𝑗是主存块号,𝑆是组数
- s = 𝑗 𝑚𝑜𝑑 𝑆
- K-路(K路:每组有多少行)组关联映射:
- 𝐾 = 𝐶/𝑆 (总行数column/总组数segment)(小心考试弄反)
标记:地址中最高𝑛位,𝑛 = 𝑙𝑜𝑔2𝑀 − 𝑙𝑜𝑔2𝑆
主存地址映射为:标记 | Cache组号 | 块内地址
4.三种比较
• 关联度(Correlation):一个主存块映射到cache中可能存放的位置个数
• 直接映射:1
• 关联映射:𝐶
• 组关联映射:𝐾
• 关联度越低,命中率越低
• 直接映射的命中率最低,关联映射的命中率最高
• 关联度越低,判断是否命中的时间越短(即搜索成本越低)
• 直接映射的命中时间最短,关联映射的命中时间最长
• 关联度越低,标记所占额外空间开销越小(即标记长度越短)
• 直接映射的标记最短,关联映射的标记最长
3.3 替换算法
- 采用替换算法的情景是,多行可选且多行均被占(直接映射不需要算法,直接换)
- 替换算法通过硬件来实现
- 设计替换算法的目标是提高命中率(比随机好)
最近最少使用算法(Least Recently Used, LRU)
假设:最近使用过的数据块有可能会被再次使用
策略:替换在cache中最长时间未被访问的数据块
2路组实现实例:
 image-20221103165510353
image-20221103165510353
4路组实例:
 image-20221103170805466
image-20221103170805466
即:命中时清零,其他加一。
未命中时,淘汰k-1的,其他加一
先进先出算法(First In First Out, FIFO)
• 假设:最近由主存载入Cache的数据块更有可能被使用
• 策略:替换掉在Cache中停留时间最长的块
• 实现:时间片轮转法 或 环形缓冲技术
• 每行包含一个标识位
• 当同一组中的某行被替换时,将其标识位设为1,同时将其下一行的标识位设为0
• 如果被替换的是该组中的最后一行,则将该组中的第一行的标识位设为0
• 当将新的数据块读入该组时,替换掉标识位为0的行中的数据块
样例:
 image-20221103172513489
image-20221103172513489
- 与LRU的区别:LRU是访问时间,FIFO为总停留时间
最不经常使用算法(Least Frequently Used, LFU)
• 假设:访问越频繁的数据块越有可能被再次使用
• 策略:替换掉cache中被访问次数最少的数据块
• 实现:为每一行设置计数器LFU
- 与LRU的区别:LRU是访问时间,LFU为访问次数
随机替换算法(Random)
• 假设:每个数据块被再次使用的可能性是相同的
• 策略:随机替换cache中的数据块
• 实现:随机替换
• 随机替换算法在性能上只稍逊于使用其它替换算法
3.4 写策略
主存和cache的一致性
- cache被替换时,需考虑该cache数据块是否被修改
替换时
- 如果没被修改,则该数据块可以直接被替换
- 如果被修改,则在替换之前必须将修改后的数据块写入主存
写策略
• 写直达(Write Through)
• 写回法(Write Back)
缓存命中时的写策略
- 写直达
• 所有写操作同时对cache和主存进行
• 优点:确保主存中的数据总是和cache中的数据一致,总是最新的(例如多CPU同步的场景)
• 缺点:产生大量的主存访问,减慢写操作
• 搭配写不分配
- 写回法
• 先更新cache中的数据,当cache中某个数据块被替换时,如果它被修改了,才被写回主存
• 利用一个脏位(dirty bit)或者使用位(use bit)来表示块是否被修改
• 优点:减少了访问主存的次数
• 缺点
• 部分主存数据可能不是最新的(例如未发生替换但需要读主存的场景)
• I/O模块存取时可能无法获得最新的数据,为解决该问题会使得电路设计更加复杂且有可能带来性能瓶颈
• 搭配写分配
缓存未命中时的写策略
• 写不分配(Write Non-Allocate):直接将数据写入主存,无需读入cache
• 优点:避免cache和主存中的数据不一致
• 通常搭配:写直达
• 写分配(Write Allocate):将数据所在的块读入cache后,在cache中更新内容
• 优点:利用了cache的高速特性,减少写内存次数
• 通常搭配:写回法
3.5 行大小
Cache命中率先升后降
假设从行的大小为一个字开始,随着行大小的逐步增大,则Cache命中率会增加
- 原因:装入了更多数据
行大小变得较大之后,继续增加行大小,则Cache命中率会下降
- Cache容量一定的前提下,较大的行会导致Cache中的行数变少,导致装入cache中的数据块数量减少,进而造成数据块被频繁替换
- 每个数据块中包含的数据在主存中位置变远,被使用的可能性减小
行大小与命中率之间的关系较为复杂
- 行太小,行数太多反时间局部性
- 行太大,行数太少反空间局部性
3.6 Cache数目
- 一级
- cache与处理器至于同一芯片
- 减少处理器在总线上的执行时间
- 多级
- 当L1(一级缓存)未命中时,减少处理器对总线上DRAM或ROM的访问
- 使用单独的数据路径,代替系统总线在L2缓存和处理器之间传输数据,部分处理器将L2(二级缓存) cache结合到处理器芯片上
统一VS分立
- 统一
- 更高的命中率,在获取指令和数据的负载之间自动进行平衡
- 只需要设计和实现一个cache
- 分立
- 实现多个cache
- 消除cache在指令的取值/译码单元和执行单元之间的竞争,在任何基于指令流水线的设计中都是重要的