
计算机组成原理-学习笔记15-指令流水线
计算机组成原理-学习笔记15-指令流水线
1. 指令周期
1.0指令周期纵观
定义:处理单个指令的过程
分为取指周期、执行周期
 image-20221208163611041
image-20221208163611041
并非所有指令的周期都一样
带中断的指令周期
 image-20230210114423694
image-20230210114423694
间址周期
把间接地址的读取看成是一个额外的指令子周期
提出目的:与数据流,指令流水线有关
 image-20230210114806911
image-20230210114806911
在指令周期中的CPU
任务
- 取指令: CPU必须从存储器(寄存器、 cache、 主存) 读取指令
- 解释指令: 必须对指令进行译码, 以确定所要求的动作
- 取数据: 指令的执行可能要求从存储器或输入/输出(I/O) 模块中读取数据
- 处理数据: 指令的执行可能要求对数据完成某些算术或逻辑运算
- 写数据: 执行的结果可能要求写数据到存储器或I/O模块
需求:寄存器
- 临时保存指令数据
- 记录当前指令位置
- (需要小容量的内部储存器)
- 假定CPU已有的寄存器
- MAR存储地址
- MBR存储缓冲/MDR存储数据
- IR指令寄存器
- PC程序计数器
1.1取指周期
流程:
 image-20230210115704765
image-20230210115704765
 image-20230210115825621
image-20230210115825621
- PC->MAR->地址总线
- 控制器通过控制线通知存储器地址就绪
- 存储器读取地址 地址总线->存储器
- 存储器通过数据总线将(指令)数据发送给MBR->IR
- 如果是异步总线,存储器提供反馈 ,告知准备好了
- 指令取回来后, PC+“1” (未画出,为控制器->PC)
1.2间址周期
 image-20230210120043533
image-20230210120043533
 image-20230210120208616
image-20230210120208616
- 将MBR缓存中的地址引用送入MAR得到地址(MAR可认为与地址总线绑定,MBR可认为与数据总线绑定)
- MAR将地址传入地址总线
- 控制器通知存储器取地址
- 存储器通过数据总线将有效地址发送给MBR
实际上间址周期取回的是一个有效地址,不是操作数本身。取操作数在执行周期
1.3中断周期
中断周期的任务:处理中断请求。需保存旧地址和旧地址内容
假设程序断点存入堆栈中,并用SP指示栈顶地址,进栈操作是先修改栈顶指针,后存入数据。
 image-20230210120613987
image-20230210120613987


箭头往右,说明都是写的操作
- 处理中断前,将下一条指令放到MBR中,再放到数据总线上 (以告知下一条指令需要返回到哪)(存入断点)
- 控制器将下一条指令的取值地址通过MAR放到地址总线上
- 控制器通知存储器获得数据
- 存储器从地址线获得地址
- 存储器从数据线获得数据,并将数据写入到获得的地址
2.指令流水线
- 流水处理(pipelining)
- 如果一个产品要经过几个制作步骤,通过把制作过程安排在一条装配线上,多个产品能在各个阶段同时被加工
- 指令流水线:一条指令的处理过程分成若干个阶段,每个阶段由相应的功能部
件完成 image-20230210152420723
image-20230210152420723
2.1两阶段方法
- 将指令处理分成两个阶段:取指令和执行指令
- 在当前指令的执行期间取下一条指令
- 问题: 执行时间一般要长于取指时间
- 性能瓶颈,工作量分配不均匀
- 主存访问冲突
- 条件分支指令使下一条指令的地址是未知的(导致原指令作废,执行指令需等待)
2.2六阶段方法
为了进一步的加速,流水线必须有更多的阶段
- 取指令(Fetch instruction, FI): 读下一条预期的指令到缓冲器
- 译码指令(Decode instruction, DI): 确定操作码和操作数指定符
- 计算操作数(Calculate operands, CO): 计算每个源操作数的有效地址
- 取操作数(Fetch operands, FO): 从存储器取出每个操作数,寄存器中的操作不需要取
- 执行指令(Execute instruction, EI): 完成指定的操作。若有指定的目的操作数位置,则将结果写入此位置
- 写操作数(Write operand, WO): 将结果存入存储器
各个阶段所需要的时间几乎是相等的 。
 image-20230210154320143
image-20230210154320143
问题
- 不是所有指令都包含6个阶段
- 例:一条LOAD指令不需要WO阶段
- 为了简化流水线硬件设计,在假定每条指令都要求这6个阶段的基础上来建立时序
- 不是所有的阶段都能并行完成
- 例: FI、 FO和 WO都涉及存储器访问
- 若6个阶段不全是相等的时间,则会在各个流水阶段涉及某种等待
- 以最长的为基准
条件转移指令损失图解
 image-20230210154624695
image-20230210154624695
 image-20230210155033296
image-20230210155033296
 image-20230210155042586
image-20230210155042586
本质:转移指令需要清空流水线造成的损失
2.3流水线性能
 image-20230210155218162
image-20230210155218162
𝑡𝑚 = max [𝑡𝑖]
单周期时间:𝑡 = max [𝑡𝑖] + 𝑑 = 𝑡𝑚 + 𝑑
总时间:𝑇𝑘,𝑛 = [𝑘 + 𝑛 - 1] 𝑡(理想情况)
加速比 = 没有使用流水线 / 使用流水线 > 1
 image-20230210155433099
image-20230210155433099
根据公式推导加速
- 误解
- 流水线中的阶段数越多,执行速度越快
- 原因
- 将数据从一个缓冲区移动到另一个缓冲区以及执行各种准备和传递功能都涉及一些开销(比如锁存延时)
- 处理内存和寄存器依赖以及优化管道使用所需的控制逻辑数量随着阶段的增加而急剧增加
3.冒险
定义:在某些情况下,指令流水线会阻塞或停顿(stall),导致后续指令无法正确执行
类型:
- 结构冒险(Structure hazard) / 硬件资源冲突
- 不同指令同时使用相同的硬件资源,比如访存
- 数据冒险(Data hazard) / 数据依赖性
- 有些数据要等前序计算完成
- 控制冒险(Control hazard)
- 比如条件转移
结构冒险
原因: 已进入流水线的不同指令在同一时刻访问相同的硬件资源
解决
- 使用多个不同的硬件资源
- 或者分时使用同一个硬件资源 (分时复用)
 image-20230210160237237
image-20230210160237237
数据冒险
原因:未生成指令所需要的数据
 image-20230210160554784
image-20230210160554784
解决1:插入nop(啥都不做)
解决2:插入bubble
(都有时间开销)
解决3:转发(forwarding) / 旁路(bypassing)
从ALU(或ALU后的步骤)直接提前打听R1
什么时候失效:非计算指令时(如load)
 image-20230210160712506
image-20230210160712506
解决方案4:交换指令顺序
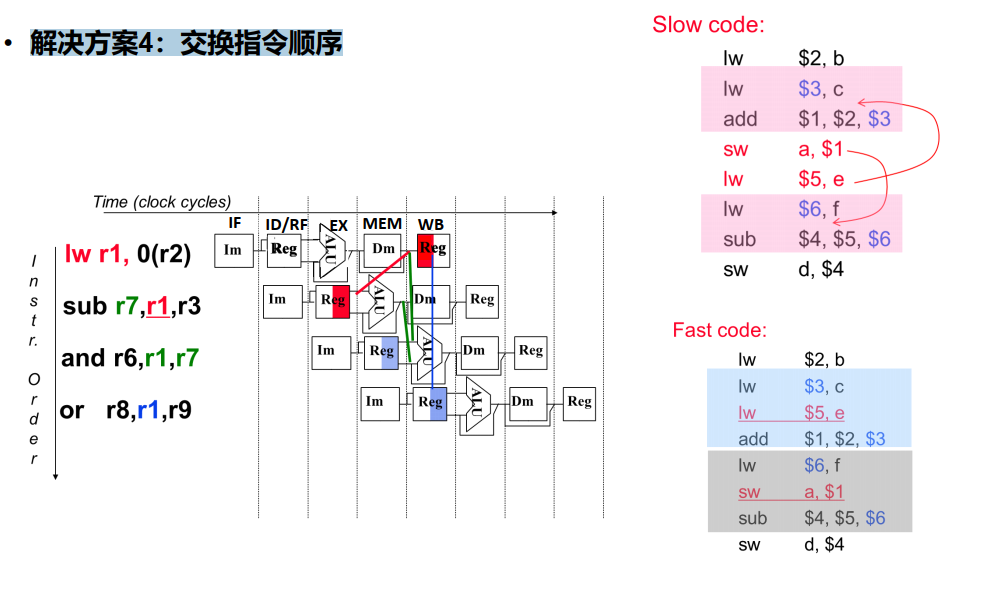 image-20230210161010109
image-20230210161010109
控制冒险
- 原因:指令的执行顺序被更改
- 转移(Transfer) : 分支(branch) , 循环(loop) , …
- 中断(Interrupt)
- 异常(Exception)
- 调用 / 返回(Call / return)
解决方案1:取多条指令
- 多个指令流: 复制流水线的开始部分, 并允许流水线同时取这两条指令, 使用两个指令流
- 预取分支目标: 识别出一个条件分支指令时, 除了取此分支指令之后的指
令外, 分支目标处的指令也被取来
缺点:指令膨胀
- 循环缓冲器: 由流水线指令取指含有 n 条最近顺序取来的指令
多线程终究有效率损害,于是有了预测
解决方案2:分支预测
- 静态预测(规则不变)
- 预测绝不发生跳转
- 预测总是发生跳转(到目标地址取指令 )
- 依操作码预测
- 动态预测(规则变化)
- 发生 / 不发生切换
- 转移历史表
分支动态预测
方法一:发生 / 不发生切换
 image-20230210164601006
image-20230210164601006
初始状态->两次错误时改变状态
假设:状态的连贯性
方法二:转移历史表
 image-20230210164736260
image-20230210164736260
未命中时记录转移历史,查表来预测